Flume-ng工作原理简介
00 概述
最近参与了公司数据收集平台的开发,对Flume做了一点简单的了解。
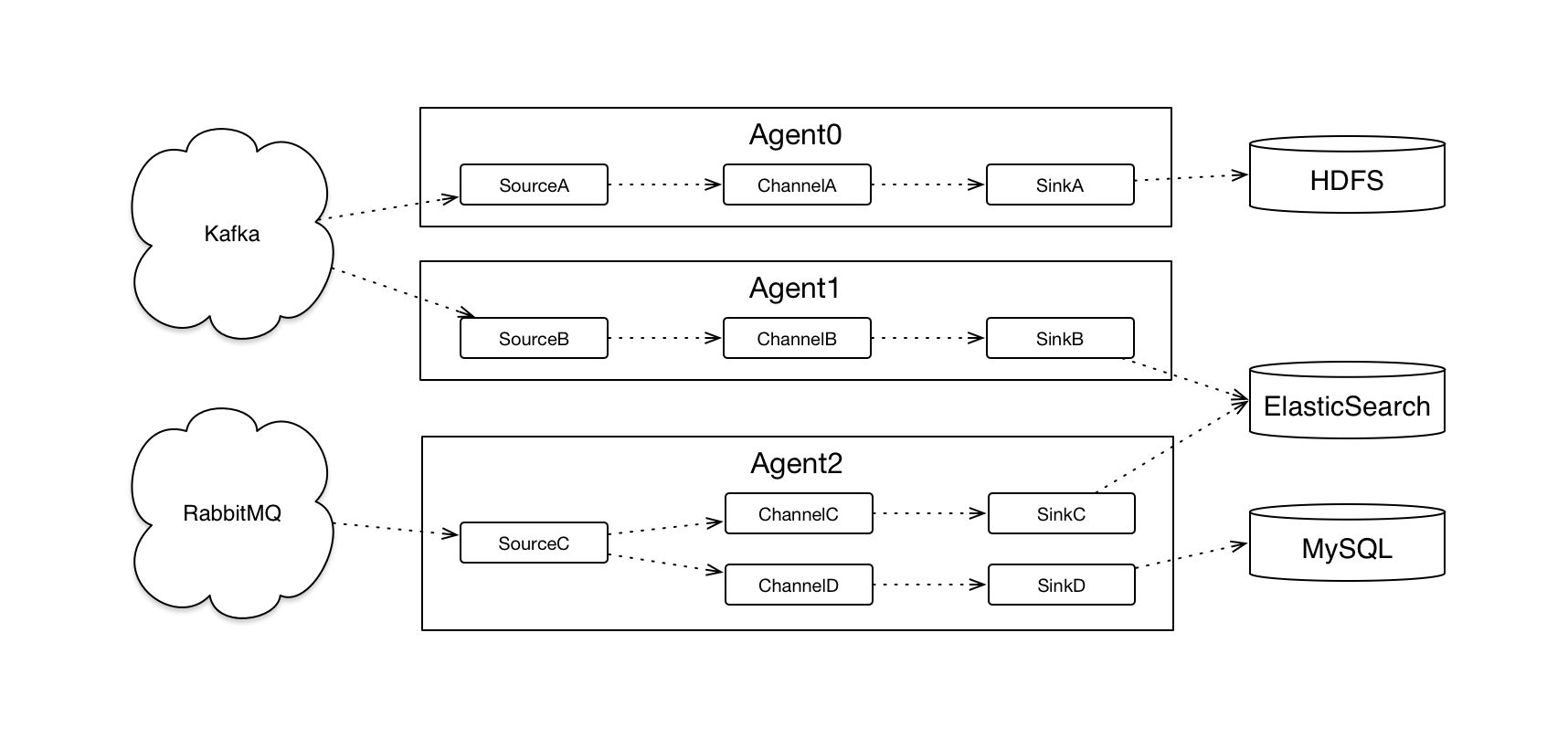
Flume从宏观上主要分为3个模块:
- Source:数据来源,如日志,消息中间件等
- Channel:管道,传输、缓冲数据,如文件系统、内存等,我们可以将Channel理解为管道或者队列
- Sink:数据目的地,如HDFS等 数据从Source —-> Channel —-> Sink可能再到其他的Source —-> Channel —-> Sink,最终到达目的地。
Flume通过Agent将上面三个模块合理的组织起来,Agent可以想象成一个搬运工,数据从A收集到B,中间可能经历1-N个搬运工。
我们可以用下面这个图来描述Flume的工作流程
01 数据抽象Event
数据在Flume的Scope中有一个统一的抽象—Event,包括两部分
- Header,一个Map
- Body,byte数组
Header的数据可以落地,也可以不落地,增强了灵活性和扩展性,Body就是真正的数据了。
02 搬运工Agent
Agent是如何工作的呢?
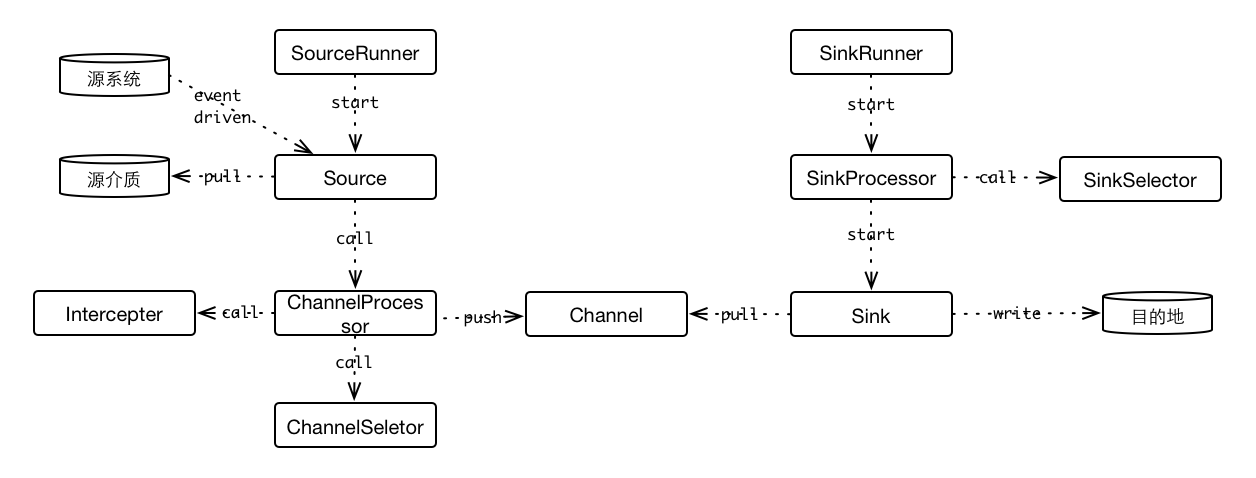
021 Source
Source通过SourceRunner来启动。SourceRunner有两个实现类:
- PollableSourceRunner
- EventDrivenSourceRunner
PollableSourceRunner为PollableSource设计,内部使用一个线程,轮询获取Event,而EventDrivenSourceRunner没有这个轮询线程,直接依赖外部的事件触发来获取Event。
典型PollableSource有KafkaSource和JmsSource,这都是典型的轮询拉模式,其他的Source,如HttpSource依赖Http请求来触发元数据获取事件。
SourceRunner内部依赖一个Source实例,所以上面两种SourceRunner都会调用实际的Source实例来获取Event,区别就是触发方式。
Source获取Event之后,就要把Event传递给Channel,这一步会委托ChannelProcessor,ChannelProcessor提供单个/批量的Event操作方法,但是并不是简单的放进去,ChannelProcessor内部还委托Interceptor和ChannelSelector做了一些其他工作。
Interceptor拦截器,负责对Event做一些修饰和过滤,如
- 对数据做一个替换
- 给Event增加时间戳
- 过滤不符合条件的Event
总之实现并配置需要的Interceptor,就可以在Event从Source进入Channel的过程中,做一些定制化的操作。
ChannelSelector用来选择合适的Channel,有两个实现:
- MultiplexingChannelSelector
- ReplicatingChannelSelector
MultiplexingChannelSelector用来做分流,譬如Event的header有个属性,值可能A|B|C,不同值的Event我们希望进入到不同的Channel。
ReplicatingChannelSelector用来做复制,譬如Event我们既想记录到HDFS持久化,也想到spark做一些实时的计算,Event需要同时进入到两个Channel,然后到不同的Sink去。
通过Interceptor的处理后,Event会进入到ChannelSelector选择的Channel中。
022 Channel
不同的Channel实现有不同的处理Event的方式,但都支持Transaction。
- MemoryChannel:内存缓冲,速度快,容量受限于内存,较小,会丢数据
- FileChannel:使用磁盘缓冲,速度慢,容量大,不会丢数据
- SpillableMemoryChannel:内存和磁盘切换,当Event个数较少时,使用内存缓冲,大于阈值后切换成使用磁盘缓冲,会丢数据
- KafkaChannel:使用Kafka做缓冲
Event进入Channel的具体步骤为:
- Channel.getTransaction
- Transaction.begin(实现是空方法,什么都不做)
- Channel.putEvent(一次 OR 多次)
- Transaction.commit OR Transaction.rollback
Event出Channel的具体步骤为:
- Channel.getTransaction
- Transaction.begin(实现是空方法,什么都不做)
- Channel.takeEvent(一次 OR 多次)
- Transaction.commit OR Transaction.rollback
023 Sink
Sink通过SinkRunner来启动。SinkRunner内部有一个线程,轮询的方式调用SinkProcessor,SinkProcessor再调用Sink,Sink再去Channel获取Event,最后写入到目标介质中。
SinkProcessor有三个实现类:
- FailoverSinkProcessor:内部配置多个Sink,当一个出错时,故障转移
- LoadBalancingSinkProcessor:依赖SinkSeletor,SinkSeletor内部可能有一个或者多个Sink,选择不同的Sink,负载均衡
- DefaultSinkProcessor:默认依赖一个指定的Sink
通过很多这样的Agent,数据可以方便移动到不同的存储介质中。
03 使用场景
031 收集日志
通常Flume会以Agent的方式部署到所有的机器上,使用ExecSource作为数据源,执行tail -F操作指定目录(约定好的),按行解析日志(日志格式要统一),然后发送到Kafka集群中,Kafka后面可以根据业务的需要,继续用Agent导入到HDFS、Hbase、ES中,或者使用Spark做实时分析。
04 总结
Flume是一个优秀的数据收集,迁移框架,感觉配合Kafka一起工作,可能更加灵活。